|
|

|

|

|
|
Analyzing the Networking Potential
of Public Transportation Systems
Public transportation vehicles and stops have a high networking potential given: their highly predictable mobility patterns, publicly-available real-time locations, their uniform location distribution throughout cities and time and their single administrative entity which can enforce network cooperation. In order to measure such a potential, a local case study representing the bus service offered by Grand River Transit at the Region of Waterloo in Ontario, Canada has been considered. In this project and given a mobility dataset in General Transit Feed Specification (GTFS) format, the networking potential has been measured by first preprocessing the dataset and then processing it. Data preprocessing steps include: data collecting, data sorting, data cleaning and data synthesis. Data processing steps include: stops selection optimization, inter-vehicle/stop connectivities computation and vehicles/stops clustering. The full source code of all of these data preprocessing and processing steps can be found at my "Mobility Analysis" GitHub repository. Some of the results found confirming the networking potential under consideration are also given below. Further details can be found in Chapter 4 of my Ph.D. thesis while additional animations can be found at the "Mobility Analysis" playlist of my YouTube channel.
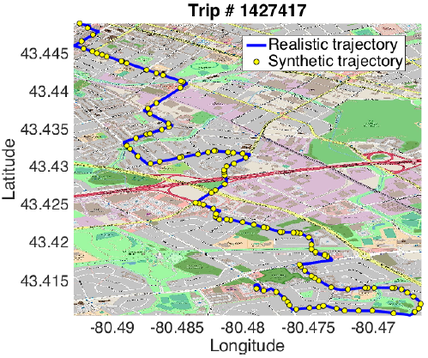
Realistic and Synthetic Trajectories Overlap of a Bus Trip Chosen at Random
|
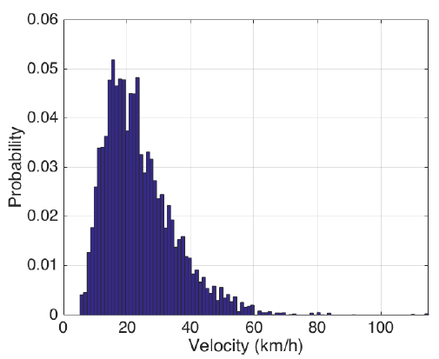
Bus Velocity Distribution After Data Synthesis
|
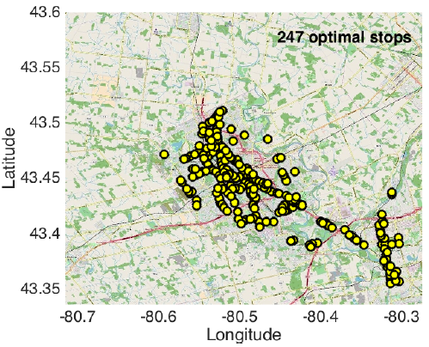
Optimal Stops Selected
(247 Stops are Selected Optimally From a Total of 2522 Stops) |
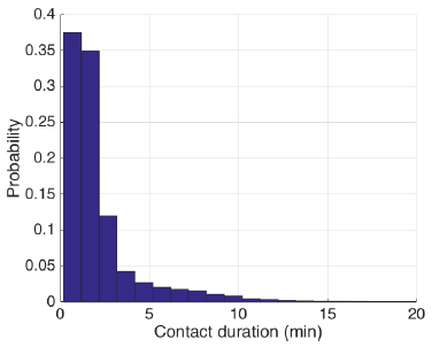
Inter-vehicle/stop Connectivity Duration Distribution
|
|
Synthetic Mobility Data Animation
|
Zoomed-in Inter-vehicle/stop Connectivities
|
Popular Content Recommendation
in Ad-hoc Network Environments
Proper content recommendations have to be made whenever popular content is distributed to consumers in ad-hoc networks. To reach this goal, different recommender systems can be implemented with different consumer interaction algorithms, different filtering techniques and different grouping techniques. Interaction algorithms differ in their exploration-exploitation tradeoffs and they include: the greedy algorithm, the epsilon-greedy algorithm, the decaying epsilon-greedy algorithm and the upper popularity bound algorithm (similar to the well-known upper confidence bound algorithm). Filtering techniques can be based on: consumer-similarities (i.e.Collaborative Filtering) or service-similarities. Grouping techniques can either: take into account the different consumer groups or just ignore them and treat all consumers as belonging to a single group. In order to decide on which recommender system is the most suitable in ad-hoc network environments, a set of experiments have been conducted as part of this project using a synthetic data set of consumer interests in a set of popular content services. Different recommender system categories have been experimented with while the full source code of all of these experiments can be found at my "Content Recommender Design" GitHub repository. Some animations are shown below while further details can be found in Chapter 5 of my Ph.D. thesis. Additional animations can be found at the "Content Recommender Design" playlist of my YouTube channel.
|
Category 2 vs. Category 3 Content Recommenders
|
Category 3 vs. Category 4 Content Recommenders
|
Popular Content Distribution
in Public Transportation
using Bayesian Optimization
With the promising networking potential of public transportation systems, a reliable vehicular network can be built using the vehicles and stops of such systems. This network can be utilized to distribute the popular content data generated by sites such as social media sites. The amount of this data represents a significant proportion of the data consumed outdoors and distributing it efficiently, by utilizing public transportation systems, would offload the overcrowded outdoor wireless networks significantly. In this project, an optimized popular content distribution system, utilizing public transportation vehicles and stops, has been designed for this purpose. This system operates in three phases: the initial V2I content distribution phase, the direct V2V data segment exchanges phase and the final V2I content distribution phase. A local case study has been considered representing the bus service offered by Grand River Transit in the Region of Waterloo, Ontario, Canada. The dataset used for this case study is in the General Transit Feed Specification (GTFS) format. To optimize the V2V segment exchanges made in the second phase, bayesian optimization has been utilized. Different regression techniques have been implemented including: gaussian processes, random forests, bayesian neural networks and batch-based random forests. The full source code of all of these implementations can be found at my "Content Routing Design" GitHub repository. Some of the results showing the V2V segment exchanges under different policies are also given below. Further details can be found in Chapter 6 of my Ph.D. thesis while additional animations can be found at the "Content Routing Design" playlist of my YouTube channel.
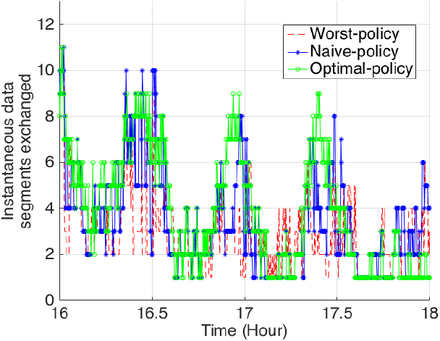
Instantaneous data segments exchanged using
V2V communication under different policies |
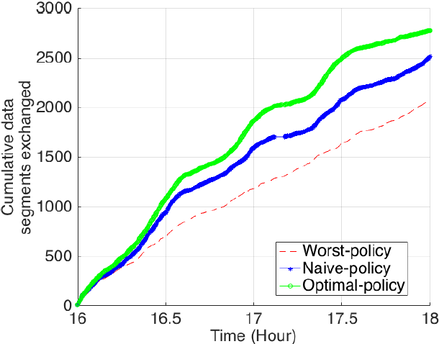
Cumulative data segments exchanged using
V2V communication under different policies |
|
|
|
